MinHash Similarity
Incentive
In my day-to-day work I’m part of the development team that develops the DAST engine of the IBM AppScan products.
In layman’s terms it means we build an engine that “mimics” the behavior of a hacker that tries to find security weaknesses in a web application.
Such hacker would look at the web application as a black box, and would test several different malicious inputs to see if any response indicates a vulnerability he can exploit.
Our engine does exactly that, automatically! And therefore should be quick but still accurate.
One scenario that is very challenging for a DAST engine is when it needs to scan a web application that has thousands of pages. Usually with these kinds of web applications, it’s safe to assume that many of their pages are actually pointing to the same server-side functionality, so we can choose one page from each cluster to do the security tests on and avoid the redundancy of the others.
For example, let’s say we’re scanning cnn.com, this web application has many articles that differ only by their text content. Behind the scenes, the server-side functionality is exactly the same, and we can use this fact to only test one of these articles (pages) and safely assume that whatever we find (or don’t find) should be the same with all other similar articles.
When dealing with this problem, you want to find a way to quickly determine whether a given page is a new page that security tests should apply to, or whether it can be skipped because it is structurally similar to a previous page that was already tested.
To do so in AppScan, we’ve used the MinHash algorithm and Locality-sensitive hashing, and in this post I’ll be covering the technical details and math of these paradigms and give examples on how to use them.
A big shout-out to Ilan Ben-Bassat who came up with the idea to use MinHash and together with Erez Rokah implemented it on AppScan. And to Sagi Kedmi who helped teaching me about it, and encouraged me to write this blog post.
Quick Jump
The Basics 
Before we can go into how MinHash works, we need to first talk about the Jaacard similarity coefficient.
The Jaccard similarity coefficient on two sets A and B is defined to be:
$J(A,B) = \dfrac{|A \cap B|}{|A \cup B|}$
Important properties of the Jaccard similarity coefficient:
- If A and B are identical sets then $J(A,B) = 1$
- If A and B are disjoint sets (have no common element) then $J(A,B) = 0$
- If A and B are neither equal nor disjoint then $0 \lt J(A,B) \lt 1$
- The more common elements A and B have, the closer $J(A,B)$ gets to 1
Similarly, the less common elements A and B have, the closer $J(A,B)$ gets to 0
With these properties we can conclude that the Jaccard similarity coefficient gives us a decent estimation of how similar two given sets are.
For example, given the sets $A = \lbrace x,y,z\rbrace$ and $B = \lbrace r,x,z\rbrace$ we get:
$J(A,B) = \dfrac{|A \cap B|}{|A \cup B|} = \dfrac{|\lbrace x,z\rbrace|}{|\lbrace x,y,z,r \rbrace|} = \dfrac{2}{4} = 0.5 = 50\%$
So far we’ve seen how we can compare how similar two sets are using the Jaccard similarity coefficient. But how will we compare two documents with it?
We can do that by treating a document as a set of words, meaning to convert the document: “Hello world, my name is Daniel.” into $\lbrace hello, world, my, name, is, daniel\rbrace$
But this approach is flawed as we don’t consider the context of a word within the text, just its existence.
A simple example of this problem would be these two documents:
- “Hello world, my name is Daniel!”
- “My name is Daniel, hello world!”
The Jaccard similarity coefficient of these two documents is 1 since they have the exact same words. But these are not identical documents, so we should get a value less than 1.
We fix this issue by introducing a new concept called Shingling.
Shingling (or w-shingling) in the document sense, is to take every continuous w words in the document and consider them as an element of the set.
In the example above, we can choose to shingle every 3 words, and end up with these sets:
$A = \lbrace hello\_world\_my, world\_my\_name, my\_name\_is, name\_is\_daniel\rbrace$
$B = \lbrace my\_name\_is, name\_is\_daniel, is\_daniel\_hello, daniel\_hello\_world\rbrace$
And now our Jaccard similarity coefficient will be $J(A,B) = \dfrac{2}{6} = 33.3\%$ which makes more sense given those two documents.
Why do we need MinHash and Locality-sensitive hashing?
At this point you might be tempted to just go ahead and use the Jaccard similarity coefficient and Shingling to start comparing your documents.
But doing that would be unwise, as you’ll eventually be facing two major issues:
- Computing the intersection and union of two sets is expensive and requires keeping the entire two sets in memory for each two sets.
- Dividing n documents into clusters of similarity will require $O(n^2)$ time complexity.
We solve the first issue by using the MinHash algorithm, and the second by using Locality-sensitive hashing concepts.
MinHash the Theory
In the previous sections we’ve seen how the Jaccard similarity coefficient can be used to estimate the similarity of two given sets, and that calculating it can be expensive. The goal of the MinHash algorithm is to estimate the Jaccard similarity coefficient quickly, without the need to go over every member of the set every time (or even to store all members in memory).
First step is to generate a random hash function h that maps members of any set S to distinct integers:
$h:S \to \mathbb{N}$
We do that in order to give a random value to each member of a set. Hash functions are convenient to use because they’re embedded in most program languages and they can produce a pseudo random integer value to every given element quickly.
Second step is to define a function that given a hash function h and a set S will return the lowest hash value of the elements of set S:
$h_{min}(S)=min(\lbrace h(x)|x\in S\rbrace)$
Taking the minimum hash value of a given set using a random hash function, is just like randomly selecting a member of the set.
Third step is to define a random variable $X_h$ such that:
$X_h=\begin{cases} 1,\ \ h_{min}(A)=h_{min}(B) \\ 0,\ \ h_{min}(A)\neq h_{min}(B) \end{cases}$
Note that the probability of two sets A and B and a given random hash function h to have the same minimum hash value is exactly J(A,B):
$\Pr(h_{min}(A)=h_{min}(B))=\dfrac{|A \cap B|}{|A \cup B|}=J(A,B)$
You can think of it intuitively as lining up all elements from the union of A and B in a random permutation, and from left to right giving each one a value from 1 to n accordingly. The leftmost element has the value 1, so it’s our minimum valued element.
If this element is in the intersection (appears in both A and B) then $h_{min}(A)=h_{min}(B)$.
Otherwise, this element appears exclusively in A or B so either $h_{min}(A)=1$ and $h_{min}(B)\gt 1$ or $h_{min}(A)\gt 1$ and $h_{min}(B)=1$. Either way $h_{min}(A)\neq h_{min}(B)$.
Therefore, this random variable has a Bernoulli distribution and takes the value 1 with probability J(A,B):
$X_h \sim \text{Bernoulli(J(A,B))}$
This is a step in the right direction since the expected value is exactly what we’re looking for $E(X_h)=J(A,B)$, but since the values of $X_h$ are strictly 0 or 1, then we can either get that A and B are identical (100% similarity) or disjoint (0% similarity).
What we need to do is get our standard deviation (the average “mistake”) as close to 0 as possible, and at the moment it’s pretty high and depends only on the value of J(A,B):
$\sigma_{X_h}=\sqrt{J(A,B)(1-J(A,B))}$
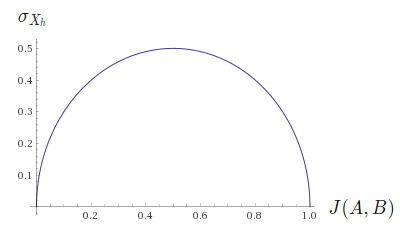
What this graph shows us is that when J(A,B) gets further away from 0 and 1, the standard deviation gets closer to 0.5 and it increases quickly. This means that we will get errors of close to 50% when J(A,B) is not 0 or 1.
Forth step instead of just using one random variable, we will average the results of n:
$\bar{X_n}=\dfrac{\textstyle\sum_{i=1}^n X_{h_i}}{n}$
Every random variable $X_{h_i}$ uses a different randomly selected hash function, and therefore they’re independent from one another. The expected value of $\bar{X_n}$ will still be J(A,B) as before:
$E(\bar{X_n})=\dfrac{\textstyle\sum_{i=1}^n E(X_{h_i})}{n}=\dfrac{\textstyle\sum_{i=1}^n J(A,B)}{n}=\dfrac{nJ(A,B)}{n}=J(A,B) \text{ }$
But this time, the standard deviation (the average “mistake”) is dependent on the number of hash functions we use:
$\sigma_{\bar{X_n}}=\sqrt{Var\Big(\dfrac{\sum_{i=1}^n X_{h_i}}{n}\Big)}=\sqrt{\dfrac{\sum_{i=1}^n Var(X_{h_i})}{n^2}}=\sqrt{\dfrac{\sum_{i=1}^n J(A,B)(1-J(A,B))}{n^2}}$ $=\sqrt{\dfrac{nJ(A,B)(1-J(A,B))}{n^2}}=\sqrt{\dfrac{J(A,B)(1-J(A,B))}{n}}=O\Big(\dfrac{1}{\sqrt{n}}\Big)$
We aim to get the standard deviation as close to 0 as possible, so the more hash functions we use, the more accurate our result will be.
For example, if we use 400 random hash functions, we can estimate J(A,B) with an average mistake of just $O\Big(\dfrac{1}{\sqrt{400}}\Big) = O\Big(\dfrac{1}{20}\Big)=\pm 5\%$
Average mistake is good, but we can do better! Since $X_{h_1},\ldots,X_{h_n}$ are independent random variables, we can use Hoeffding’s inequality to get an upper bound on the probability that $\bar{X_n}$ deviates from its expected value by more than a certain amount:
$\Pr(|\bar{X_n}-E(\bar{X_n})|\geq \epsilon)\leq 2e^{-2n\epsilon^2}$
* This inequality is the special case where the random variables have Bernoulli distribution.
We calculated the expected value already (J(A,B)), so let’s add that, and also let’s introduce $\delta$ as the upper bound we’re willing to accept:
$\Pr(|\bar{X_n}-J(A,B)|\geq \epsilon)\leq 2e^{-2n\epsilon^2}\leq \delta$
Our goal is to find the minimum n such that the probability of getting an error of more than $\epsilon$ is less than $\delta$ we’ll do some algebra and end up with:
$2e^{-2n\epsilon^2}\leq \delta$
$-2n\epsilon^2\leq ln\Big(\dfrac{\delta}{2}\Big)$
$n\geq -\dfrac{1}{2\epsilon^2}ln\Big(\dfrac{\delta}{2}\Big)$
$n\geq \dfrac{1}{2\epsilon^2}ln\Big(\dfrac{2}{\delta}\Big)$
For example, if we want the probability of getting errors bigger than 5% to be less than 3%, we’ll use $\epsilon=0.05$ and $\delta=0.03$, and end up with $n\geq 840$.
Meaning we need to use at least 840 hash functions to guarantee this bound.
MinHash in Practice
We now understand how MinHash works in theory, and we’ve seen the math behind it. But implementing it might still feel scary. Especially, the hash function part.
Luckily, as I mentioned earlier, using hash functions is convenient for us, since most modern programming languages give us a built-in hash value for every instance of a data set, and we can use that initial value to generate as many random hash values as we want using a randomly selected integers by doing xor operator between them.
Below is a Java snippet example of how you can generate n hash values (represented as randomly selected integers) and use these values to calculate the n minimum hash function values.
(what we defined as $h_{min}(A)$)
public class MinHashExample {
protected int hashFunctions[];
public MinHashExample(int numOfHashFunctions) {
hashFunctions = new int[numOfHashFunctions];
Random randomGenerator = new Random();
for (int i=0; i<numOfHashFunctions; i++) {
hashFunctions[i] = randomGenerator.nextInt();
}
}
public <T> int[] getHashMinValues(Set<T> A) {
int hashMinValues[] = new int[hashFunctions.length];
for (int i=0; i<hashFunctions.length; i++) {
hashMinValues[i] = getHashMinValue(A, hashFunctions[i]);
}
return hashMinValues;
}
protected <T> int getHashMinValue(Set<T> A, int hashFunction) {
int hashMinValue = Integer.MAX_VALUE;
for (T element : A) {
int hashValue = element.hashCode() ^ hashFunction;
hashMinValue = Math.min(hashMinValue, hashValue);
}
return hashMinValue;
}
}You can see a full example of the MinHash implementation, with different hash function generation methods, on my GitHub page:
Locality-sensitive hashing
I still owe you a detailed explanation of how to solve the second issue with the Jaccard similarity coefficient:
Dividing n documents into clusters of similarity will require $O(n^2)$ time complexity.
Since Locality-sensitive hashing is a big topic by itself, I think it deserves a post of its own.